

Microsoft Fabric is an all-in-one analytics solution for enterprises, designed to help organizations create, use, and govern data insights effectively. Within the Fabric ecosystem, Spark integration enables developers to harness the power of Apache Spark for big data processing. Spark is a powerful open-source distributed computing framework that specializes in scalability, speed, fault tolerance, and a rich set of processing capabilities.
Microsoft Spark Utilities (MSSparkUtils) is a utility library developed by Microsoft for Apache Spark. It offers a variety of helper functions and utilities to simplify common tasks such as file system operations, managing Lakehouse artifacts, retrieving environment variables, running multiple notebooks concurrently, and handling secrets. In this article, we will explore some useful techniques for leveraging MSSparkUtils in Microsoft Fabric notebooks.
MSSparkUtils in Notebook
MSSparkUtils is a built-in utility available in Fabric Notebooks. You can access it using the mssparkutils prefix. Alternatively, you can import it with a preferred alias, such as msu.

Check the Available Methods
To explore the available methods in MSSparkUtils, you can list them as shown below:


Working with Lakehouses
A Microsoft Fabric Lakehouse is a unified data storage and processing architecture that combines the benefits of data lakes and data warehouses. Using MSSparkUtils in notebooks, you can easily create, delete, or list Lakehouses within a specific workspace.
Creating a New Lakehouse
To create a new Lakehouse, use the following command:


This command creates a Lakehouse named “Primary_Lakehouse” in the current workspace. If you want to create the Lakehouse in a different workspace, you need to provide the workspace ID as a parameter.
Listing Lakehouses in a Workspace
To check the number of Lakehouses available in a workspace, use the following code:


The output may appear cluttered. To simplify, let’s extract only the names of the lakehouses. Run the following code, and feel free to customize the parameters as needed.

Create a Directory in the Lakehouse
Now that we have created a lakehouse, the next step is to create directories under the default file section of the lakehouse. Directories are essential for organizing large volumes of data. MSSparkUtils provides an inbuilt method called mkdirs that we can use for this purpose.


Copy Files to a Secondary Lakehouse
When working with data, it is often necessary to copy files from one lakehouse to another. MSSparkUtils simplifies this process by allowing you to copy files between lakehouses using notebooks. Below is an example of copying data from a primary lakehouse to a secondary lakehouse.

Move Different Types of Files Using Custom Function
In our raw_files directory, we have two types of files. We will now move these files to the secondary_lakehouse based on their file types. To achieve this, we will create a custom function using MSSparkUtils. This function will allow us to quickly move files according to their types.
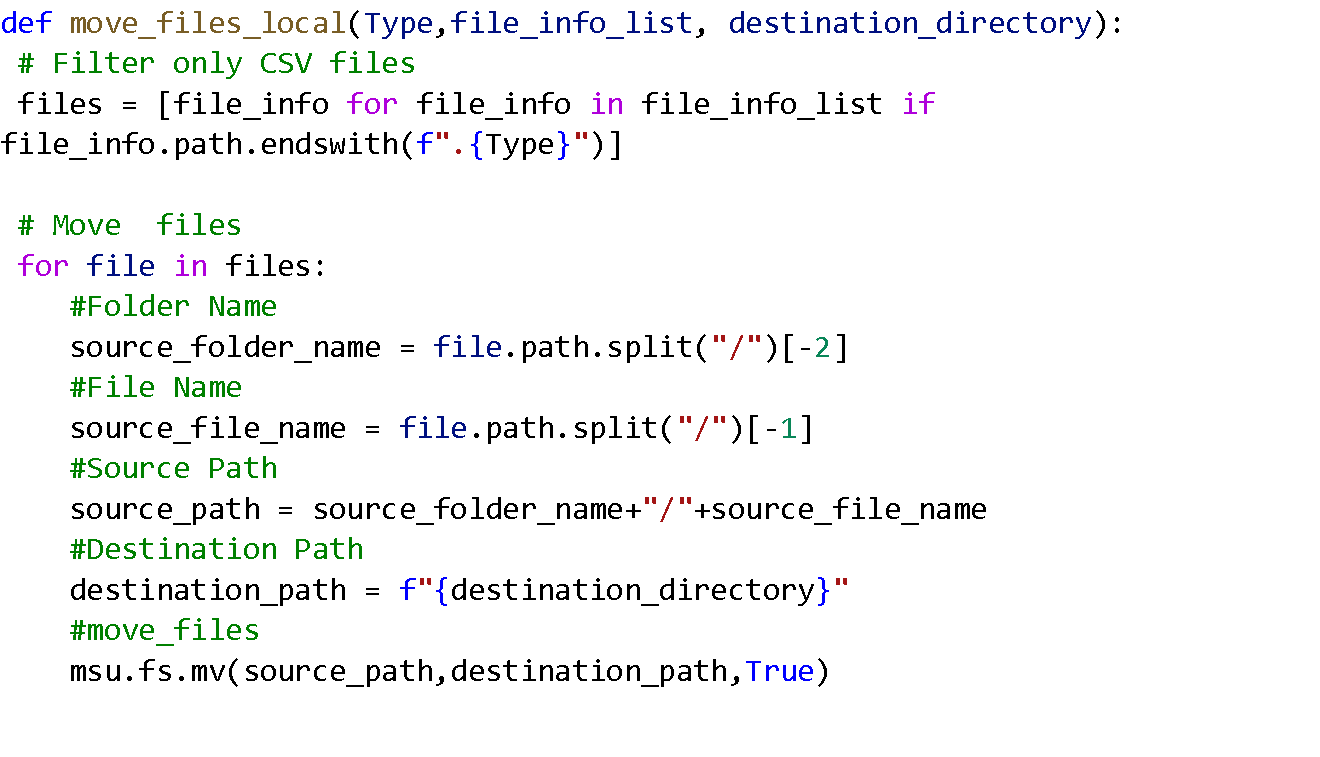
Moving Files from Local Lakehouse
Using ABFSS Path for Moving Files
If you are using an ABFSS path, try the following code:
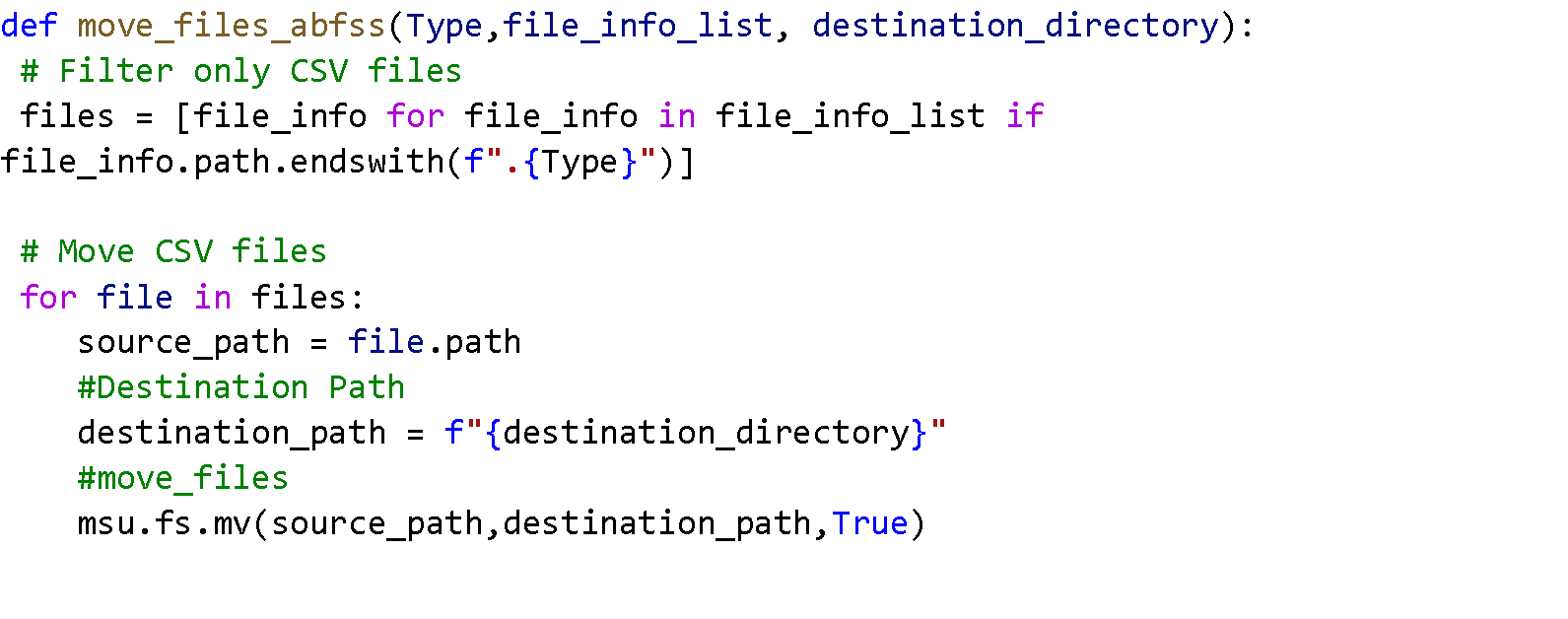
Our custom function is now ready. It accepts three parameters:
- Type: The type of files you want to move.
- file_info_list: A list of files in the source directory.
- destination_directory: The directory where you want to move the files.
You can use the first code snippet for the current mount point and the second one for moving files using an ABFSS path.
Let’s call the function to move the files. Our goal is to move specific file types one at a time.

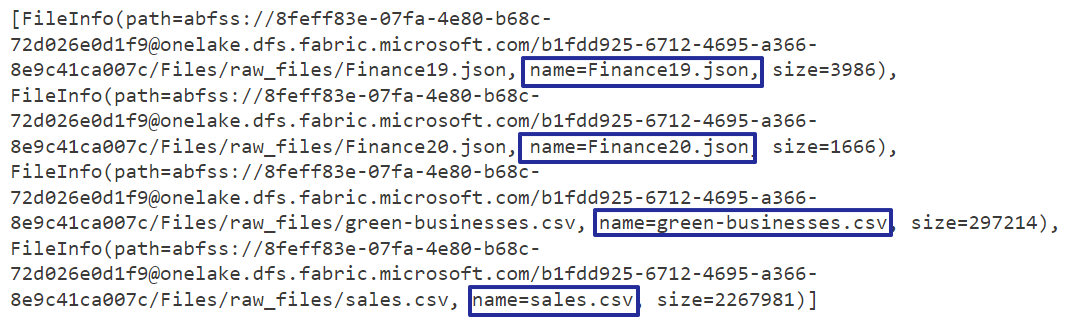

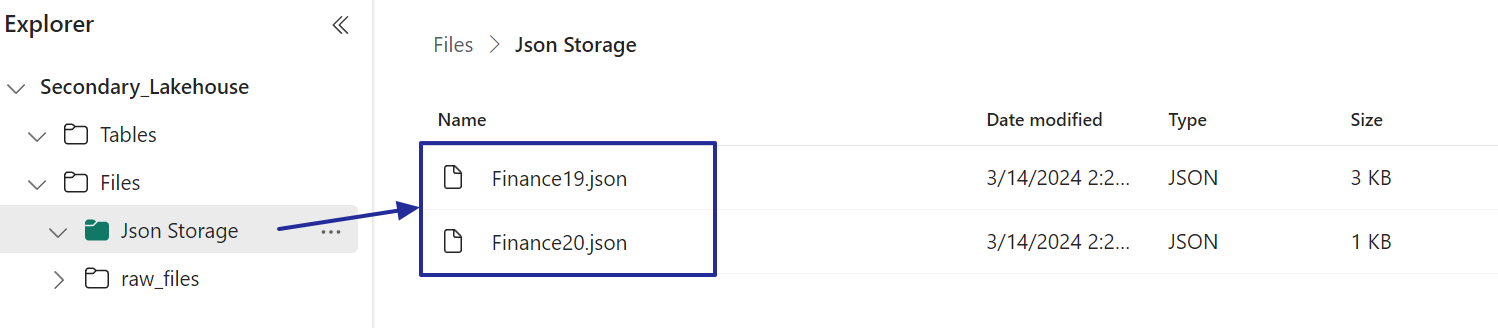
Finally, we have successfully moved the JSON files to the destination folder.
Copy (cp) vs Fast Copy (Fast cp)
Earlier in this article, we discussed two methods for copying files using MSSparkUtils: cp and fastcp. The fastcp method is designed for high-performance copying of large volumes of data, making it the preferred choice for bulk operations.

Conclusion
In conclusion, MSSparkUtils’ Lakehouse utilities significantly streamline the management of Lakehouse artifacts. By integrating these tools into your Fabric pipelines, you can enhance your data management workflows and improve efficiency.Explore more insights and tips by checking out our other articles on Microsoft Fabric here.































