

Microsoft Fabric provides a robust platform for modern data management, enabling streamlined processing and advanced analytics. Data Pipelines automate the extract, transform, and load (ETL) processes, which are essential for ingesting transactional data into analytical data stores.
In this article, we will explore the core activities and functions of data pipelines and then create a sample data pipeline using the Copy Data activity.
Data Pipeline Architecture and Use Cases
Data Pipelines in Microsoft Fabric share the same architecture as Azure Data Factory. You can run pipelines interactively through the Microsoft Fabric user interface or schedule them to run automatically.
Data Pipelines can be used in various scenarios, including:
- Big Data Processing: Data pipelines enable efficient processing of large data volumes in distributed environments like Hadoop and Spark, supporting analytics and machine learning tasks.
- Cloud Data Migration: Pipelines orchestrate data transfer and transformation tasks, streamlining data migration to cloud platforms such as AWS, Azure, and Google Cloud.
- Real-Time Data Streaming: Pipelines process streaming data from sources like IoT devices and social media in real-time, allowing for immediate insights and actions.
- Data Warehousing: By automating ETL processes, pipelines load data into warehouses, making it easier for business users to query and analyze.
- Machine Learning and AI: Pipelines prepare and pre-process data for training machine learning models, facilitating scalable model training and deployment.
Core concepts of Data Pipelines
Before creating pipelines in Microsoft Fabric, it’s important to understand some fundamental concepts. Data pipelines consist of various elements, including activities, parameters, and pipeline runs.
Activities in Data Pipelines
Activities in Microsoft Fabric’s data pipelines serve two primary purposes: data transformation and control flow. Some of the most commonly used activities include:
- Copy Data Activity: Facilitates copying data between cloud-based data stores.
- Dataflow Activity: Enables running Dataflow Gen2 in Microsoft Fabric’s Data Factory.
- Stored Procedure Activity: Executes pre-defined procedures in pipelines, streamlining database integration.
- ForEach Activity: Establishes repeating control flows by iterating over collections and executing specified activities.
- If Condition: Branches based on condition evaluation, executing different activities depending on the outcome.
- Lookup Activity: Retrieves records or values from external sources for reference by subsequen tactivities.
Parameters
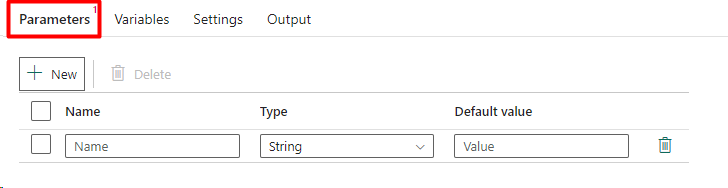
Parameters in pipelines allow for customization by providing specific values for each pipeline run. This flexibility enhances the reusability of pipelines, enabling dynamic data ingestion and transformation processes.
Pipeline Runs
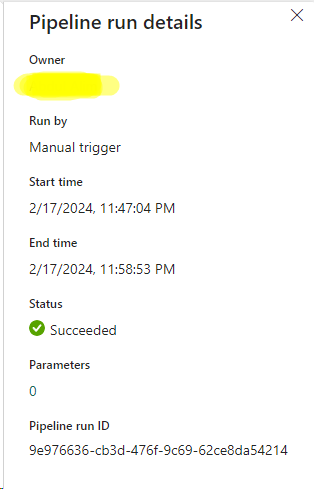
Pipeline runs are initiated each time a pipeline is executed. Runs can be started on-demand or scheduled at regular intervals. Each run has a unique ID, which can be used to review details, ensure successful completion, and examine specific execution settings.
Creating a Sample Pipeline Using the Copy Data Activity
To get started with Microsoft Fabric, follow these steps to create a sample pipeline using the Copy Data activity:
Step 1: Activate a Fabric Trial: Begin by initiating a Fabric trial in your account if you haven’t purchased Fabric capacity. Follow this link to activate your trial: Microsoft Fabric Trial.
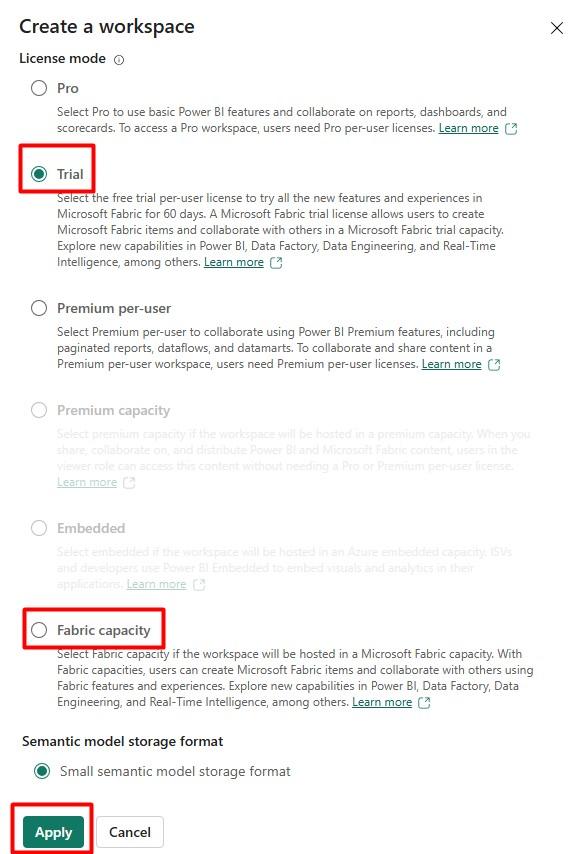
Step 2: Create a Fabric Workspace: After activating your trial or purchasing capacity, create a Fabric capacity workspace using the Fabric capacity license from app.powerbi.com.
- Select workspace icon from left side menu and click on +New Workspace button.
- Provide a name of your workspace and expand the Advanced option.
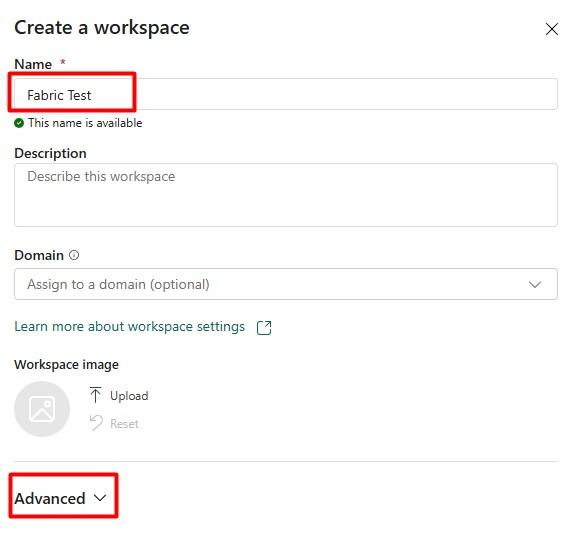
- Under advanced option select your Trial/Fabric Capacity license and click on Apply button.
Step 3: Create a Data Pipeline: If you’re not already in the workspace, navigate to it. Click the + New Item button in the top-left corner to open a pop-up on the right side. From the item list, select Data Pipeline and provide a name for it.
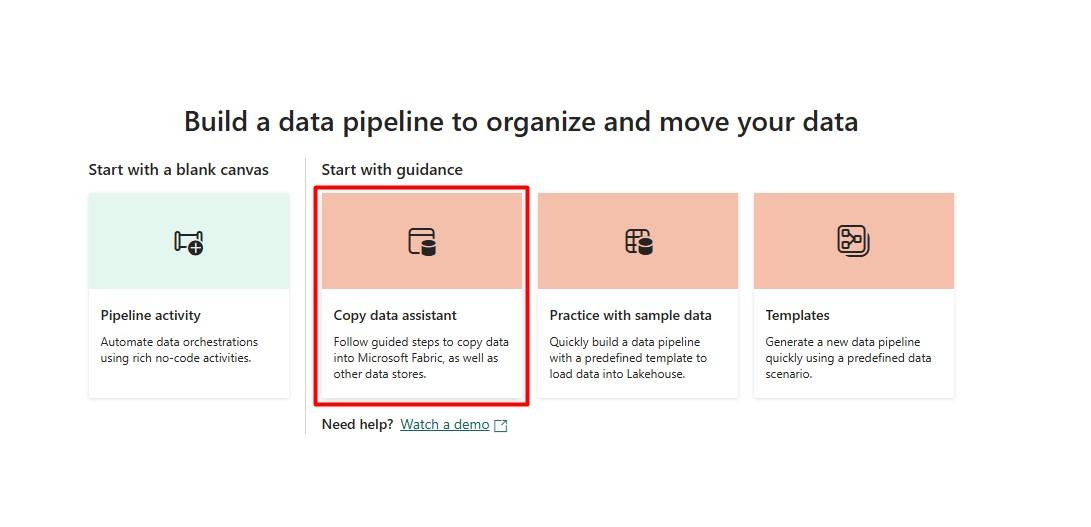
Step 4: Configure the Copy Data Activity: After creating the pipeline, you’ll be presented with an interface to configure the Copy Data activity. Select the Copy Data assistant and choose a data source from the available options. For this example, we’ll use the sample dataset titled NYC Taxi-Green.
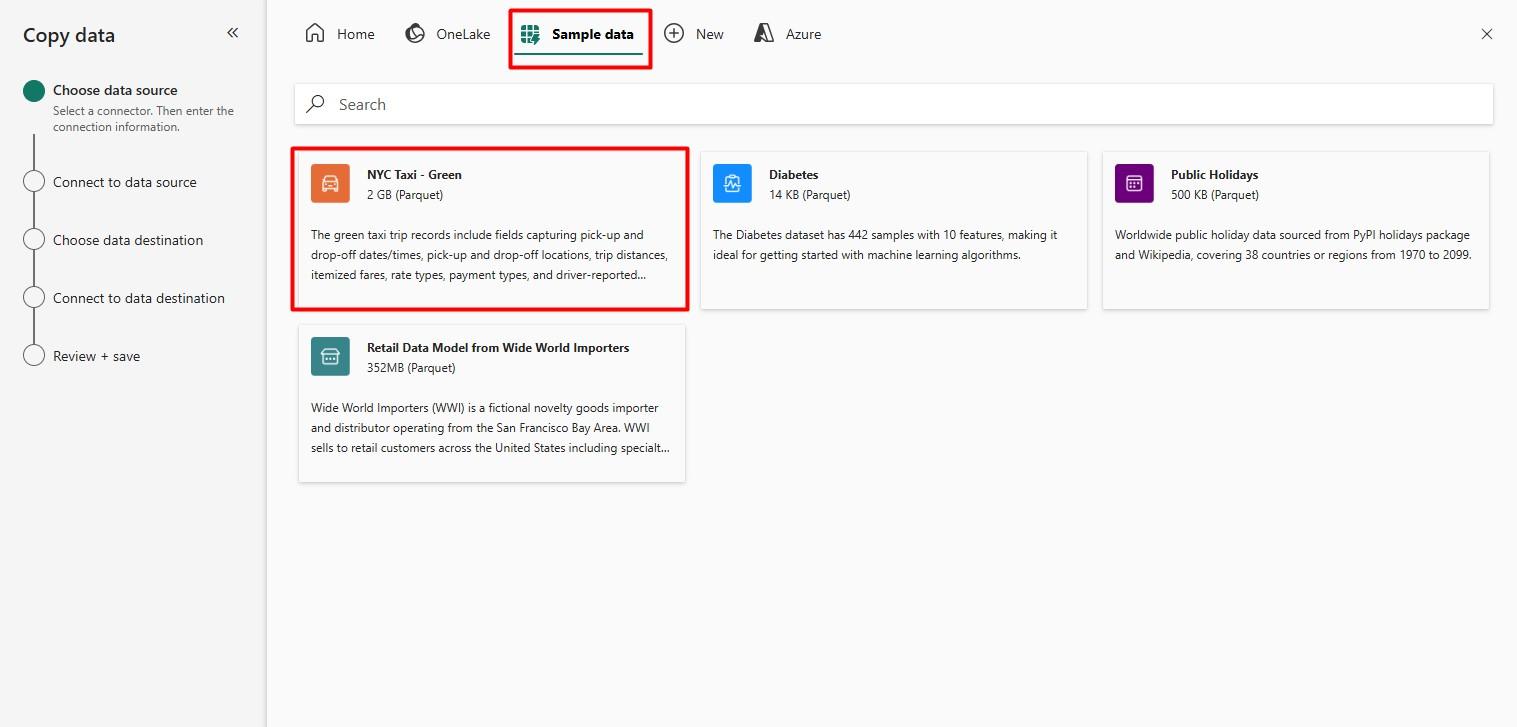
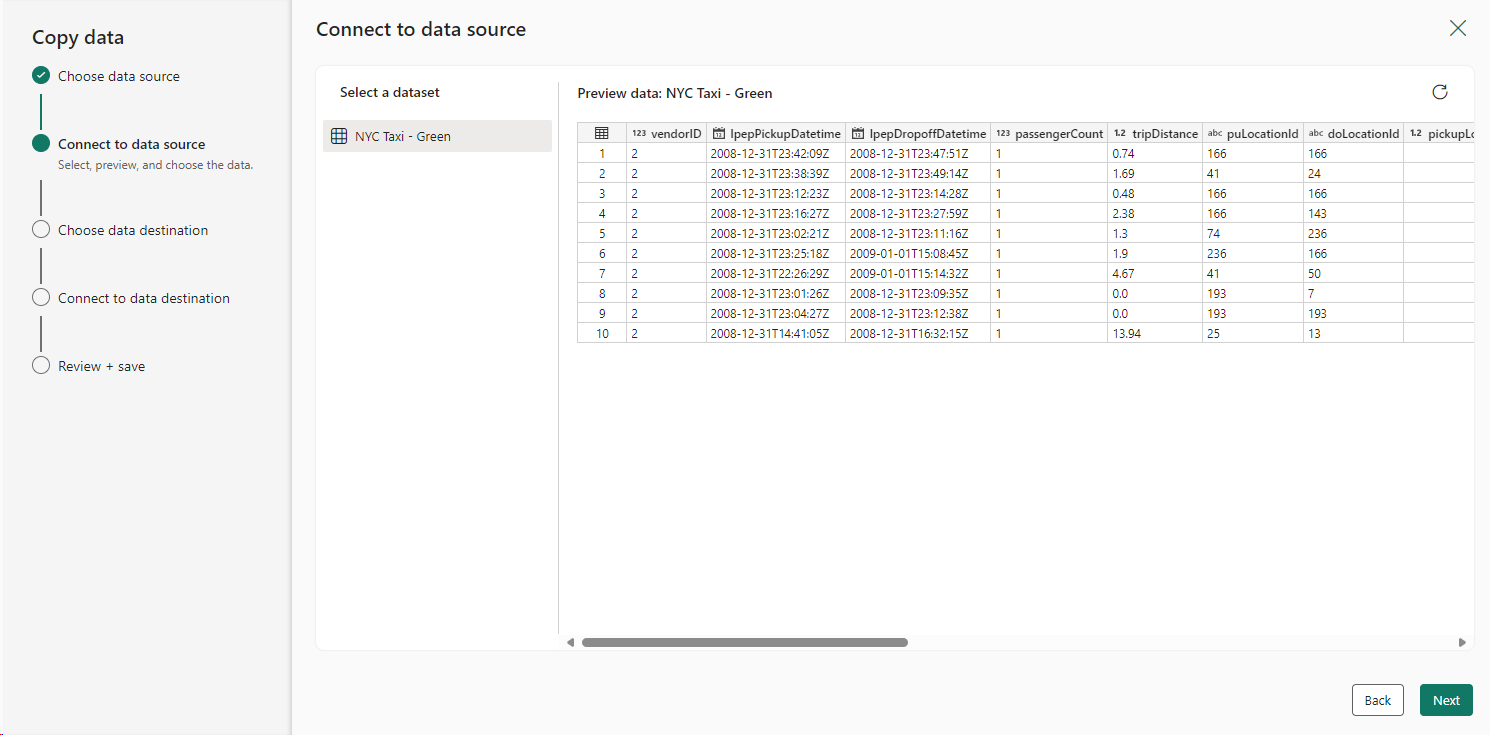
Step 5: Connect to the Data Source: After selecting the source data, click Next to proceed to the Connect to Data Source step. Here, you can preview the dataset.
Step 6: Choose the Data Destination: After reviewing the dataset, click Next to proceed to the Choose Data Destination page. Select the destination where your data will be stored. For this example, we’ll choose Lakehouse as the data destination.

Choose Lakehouse and proceed to select the specific Lakehouse where you want to store the data.
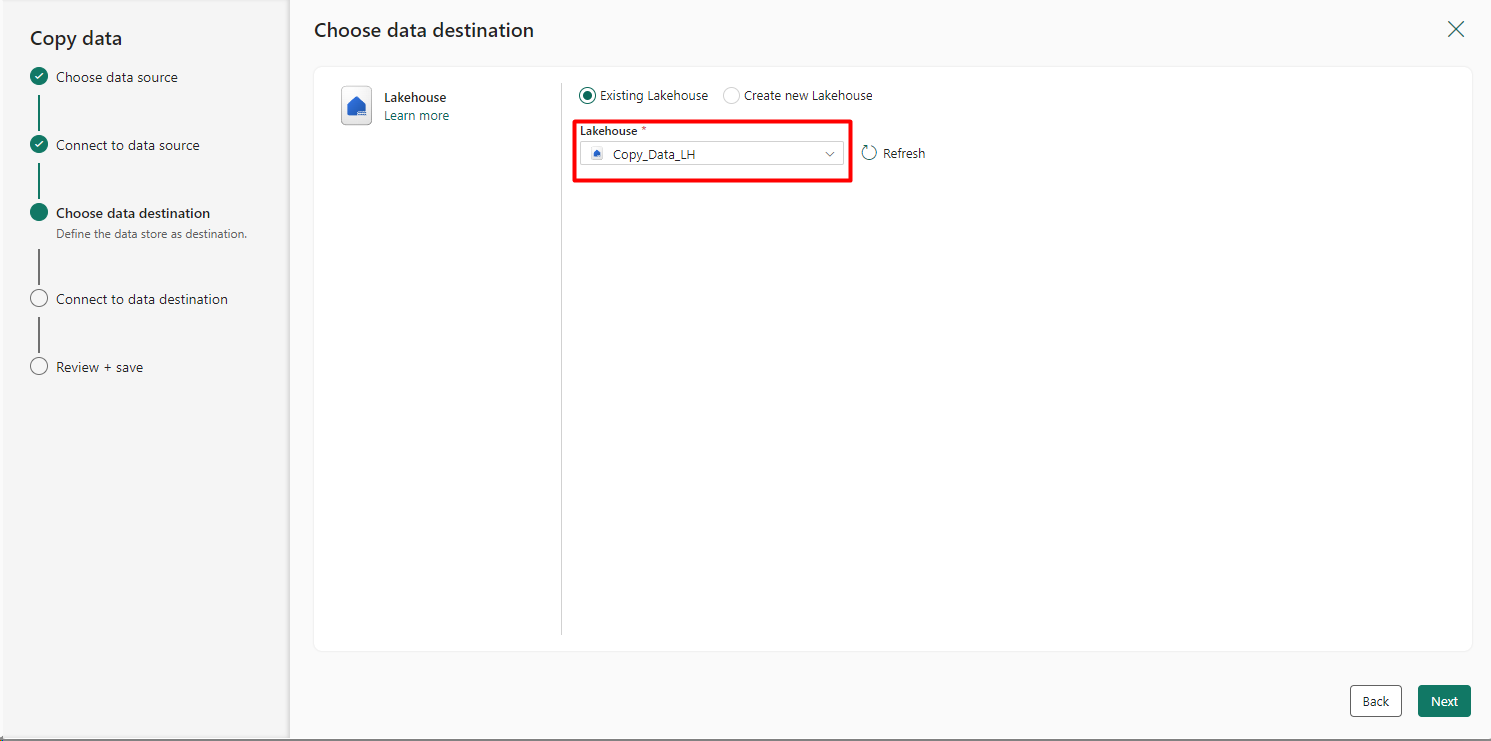
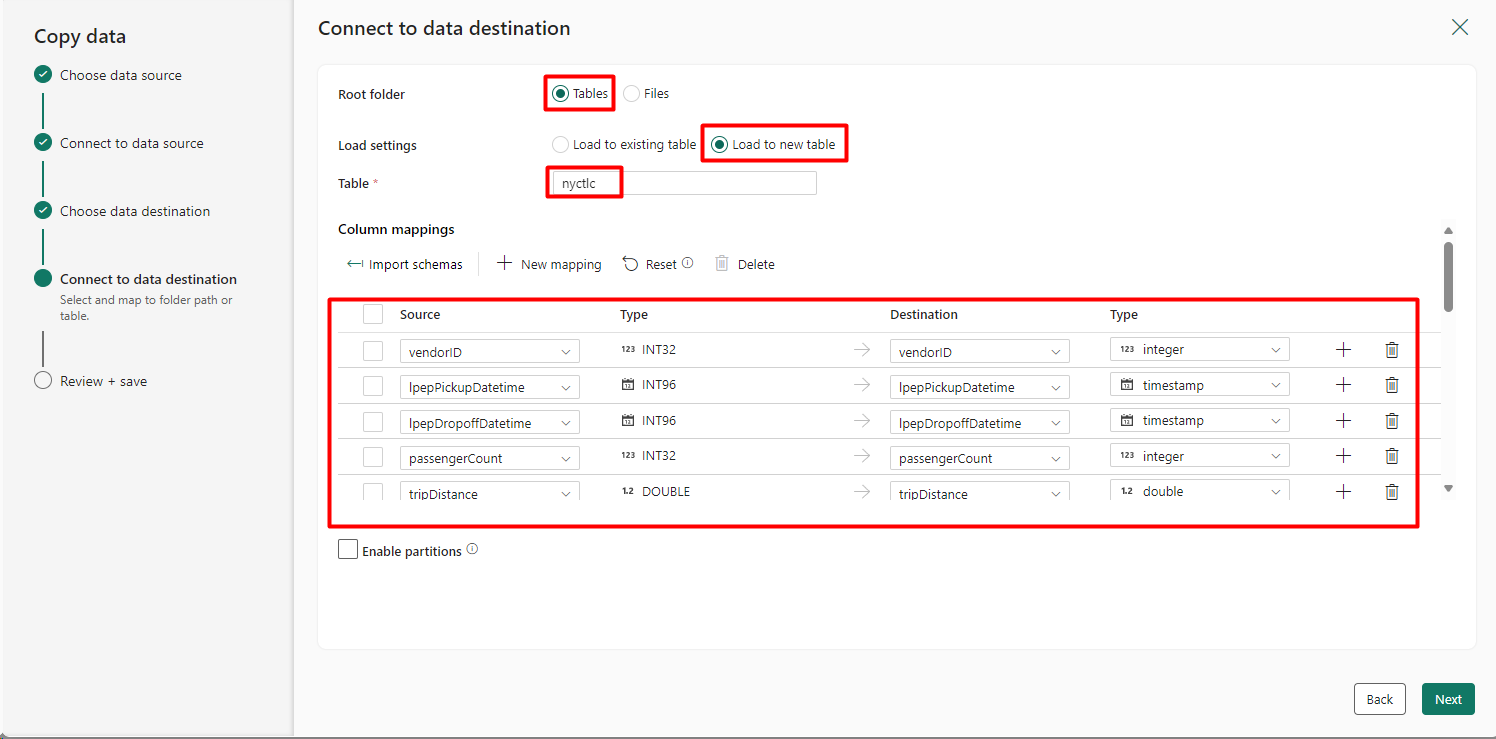
Step 7: Configure Storage Settings: After selecting Lakehouse, you’ll be prompted to configure how the dataset will be stored. Choose Tables for the Root folder and Load to New Table as the Load settings. Rename the table as desired. You also have the option to map columns if you wish to modify column names or data types.
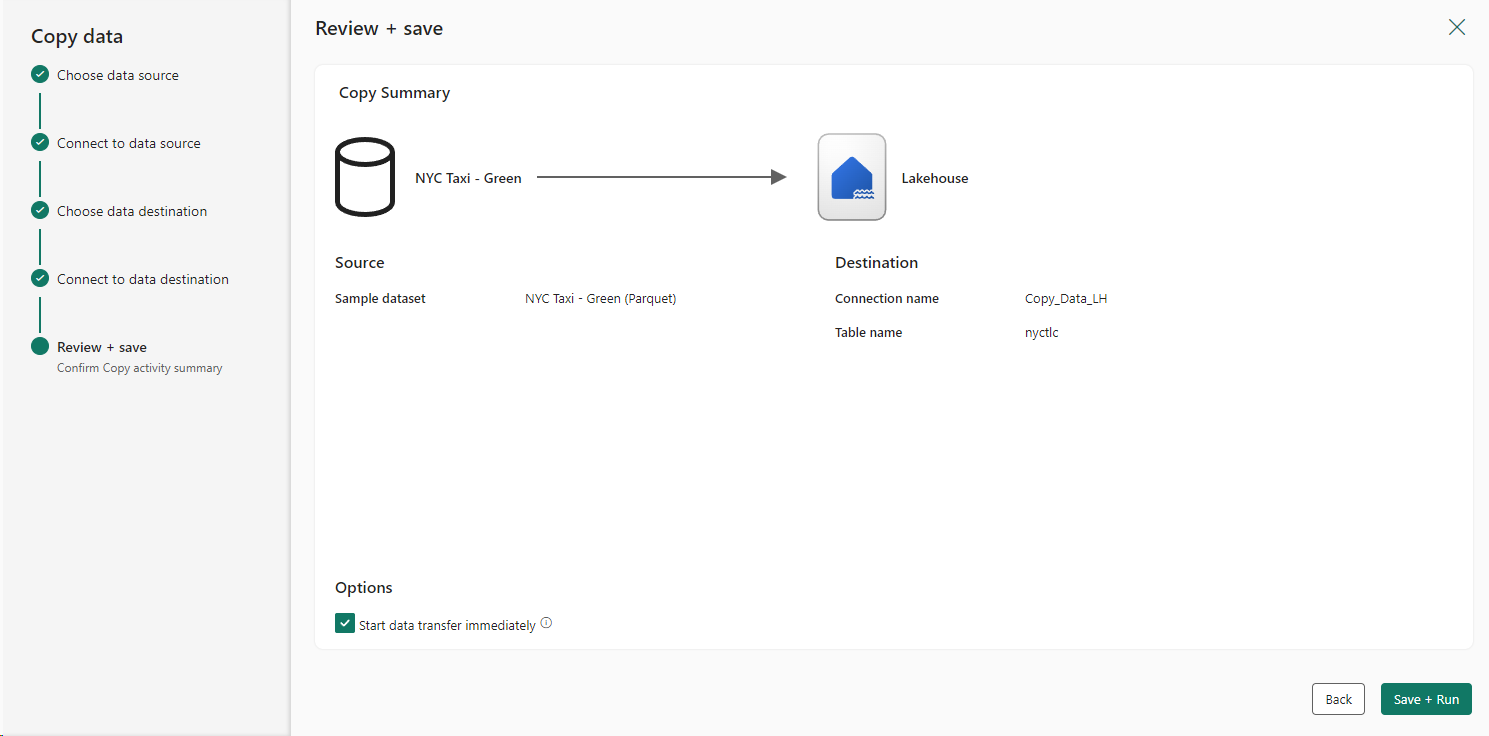
Step 8: Review and Save: Click Next to proceed to the Review + Save page, where you can review the configurations made for copying data from the source to the destination. After verifying the source and destination details, select Save + Run to save the Copy Data activity.
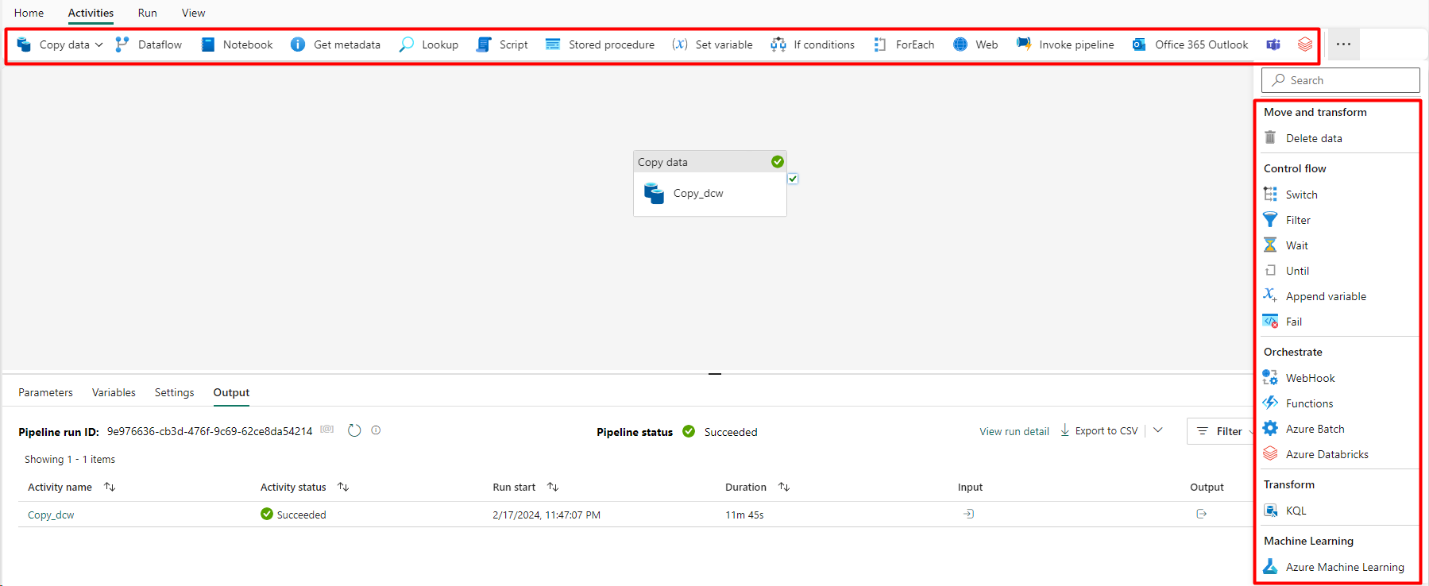
Step 9: Monitor the Pipeline Run: Once the pipeline is running, you can monitor its status from the output pane.
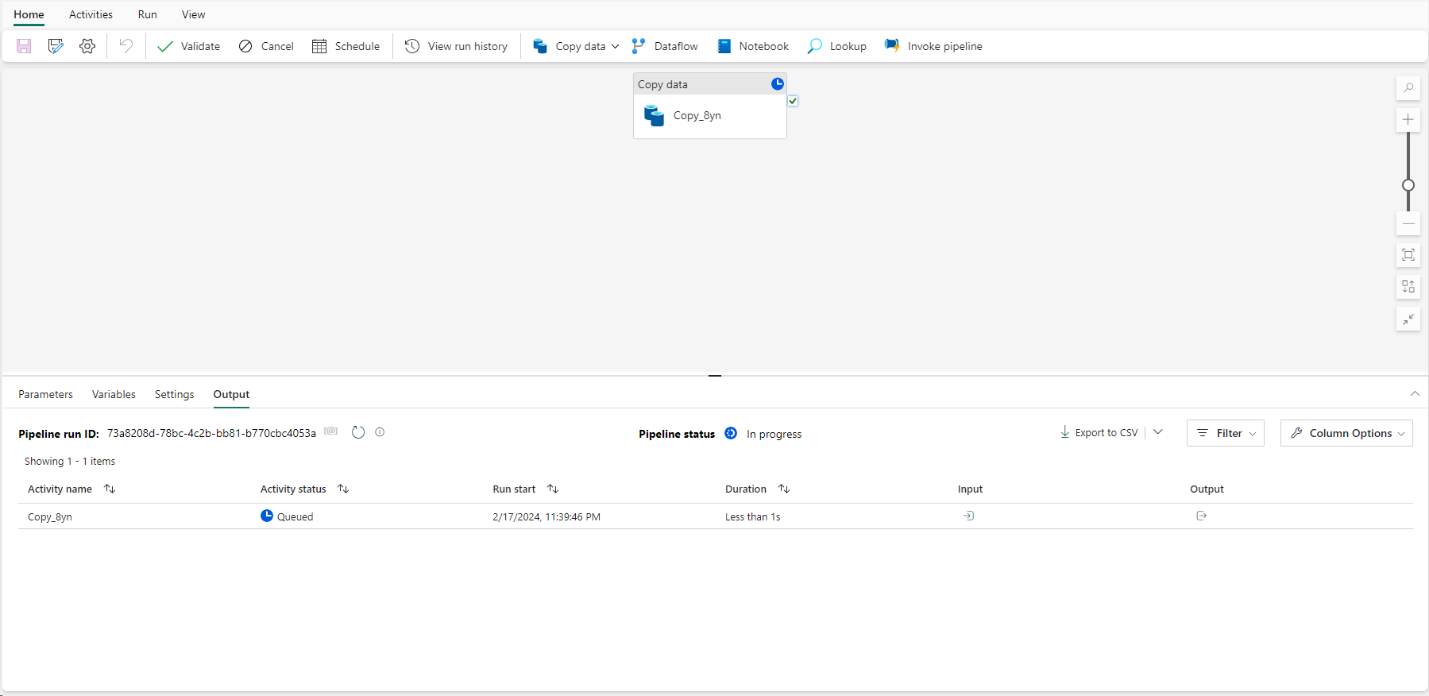
After completion, you can view all the settings under the Activities tab by selecting the Copy Data activity.
Conclusion
Microsoft Fabric’s Data Pipeline simplifies the orchestration of ETL processes and facilitates data extraction from a variety of source systems. As demonstrated in this article, core activities like Copy Data streamline tasks, while the intuitive interface enables efficient configuration for data transfer and storage. This empowers organizations to harness data effectively for actionable insights and informed decision-making.
Stay tuned for more articles in this series, where we’ll explore additional experiences within Microsoft Fabric.
































