
Choosing the right storage mode in Microsoft Fabric can make or break your analytics experience. Whether you’re working with lightning-fast dashboards or managing massive datasets, the performance difference between Direct Lake, Import, and DirectQuery modes is often underestimated.
In this blog, I’ll take you through a real-world benchmark using two datasets — one large and one small — to uncover how each mode performs under different scenarios. You’ll see where Direct Lake shines with near real-time insights, when Import delivers unmatched speed, and why DirectQuery is still the right choice for certain use cases.
If you’ve ever wondered which mode to choose and when, this comparison will give you clear, practical guidance backed by results.
Understanding Microsoft Fabric Storage Modes
Before diving deeper, let’s break down each storage mode in simple terms.
Import Mode in Power BI: Speed and Limitations
Import mode has long been the default storage mode in Power BI, known for its blazing-fast query performance thanks to the in-memory VertiPaq engine. Here, data is copied into an in-memory cache (VertiPaq engine), giving blazing-fast query performance. The trade-off is that the data is only as fresh as the last refresh, and very large datasets can run into memory or refresh-time limitations. Import works best when you need ultra-fast performance with datasets that are not too large and don’t change every second.
DirectQuery Mode in Power BI: Pros and Cons
In DirectQuery mode, data remains in the source system (SQL, Synapse, or Dataverse) and is queried live every time a report runs. This avoids data duplication and ensures latest results, but the performance depends on the source system’s speed and network latency. It’s useful when you must work with very large datasets that can’t fit in memory, or when data freshness is critical but expect slower visuals compared to Import or Direct Lake.
Direct Lake Mode in Fabric: The New Standard
Direct Lake mode in Microsoft Fabric is the newest and most innovative option, connecting Power BI directly to data in OneLake without imports or queries through an engine. It lets Power BI connect directly to data stored in OneLake without the need to import or query through an engine. Because the data is read in its native parquet format, reports feel as fast as Import mode while still being connected to a single source of truth. This is ideal for scenarios where you want real-time freshness and top performance without heavy data movement.
Benchmark Datasets Used for Testing
Here I have chosen two different datasets
Dataset One: It’s a single large flat table.
- Name: NYC Yellow Taxi Trip Data
- Size: 7.39 GB
- Rows: 47.25 million
You can download this dataset from here
Dataset Two: Small dataset, end goal is to have a star schema.
- Name: Contoso BI Demo Dataset
- Size: 492 MB (Used tables: DimProduct, DimStore and FactSales)
- Rows: Total number of rows around 3.41 million
You can download this dataset from here
Used System Configuration: All data was loaded into a Lakehouse within a Fabric capacity-enabled workspace (FT1) to keep performance conditions consistent across every test. Since the same internet connection was used for all tests, network speed didn’t affect the comparison so we can safely skip that factor and, for every run I ensure there is no cache memory.
Performance Benchmark: Direct Lake vs Import vs DirectQuery
Let’s dive into the results and see how each storage mode Import, DirectQuery, and Direct Lake behaves when tested with a large dataset (NYC Yellow Taxi, 47.5M rows) versus a smaller dataset (Contoso BI, 3.41M rows).
Case 1: NYC Yellow Taxi Data (47.5M rows)
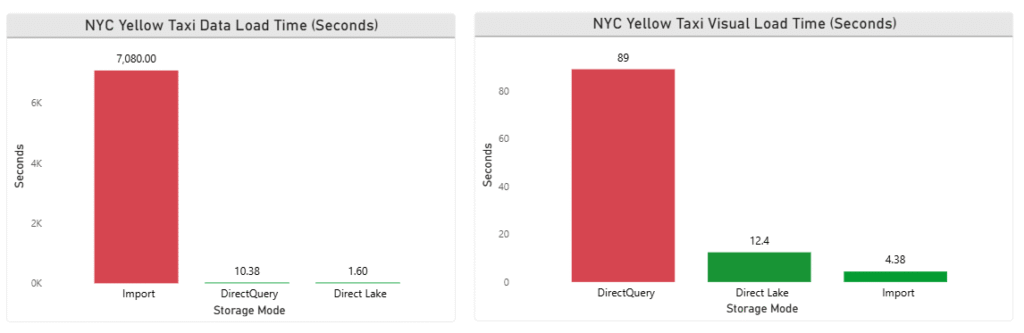
When it comes to data load time inside Power BI Desktop, the difference is jaw-dropping:
- Import mode: Took a staggering 1 hour 58 minutes to load. Like Import mode, I decided to take a very long lunch and coffee break while loading our massive NYC dataset.
- DirectQuery: loaded in just 10.38 seconds, it seems like it’s said hello sir, I am ready to get your data when you need it.
- Direct Lake: Loaded in just 1.6 seconds. It felt like showing up to watch an F1 race, only to see a supercar teleport the finish line before you could even blink, leaving your jaw hanging in disbelief.
Winner: Direct Lake by a landslide.
But wait, there’s a plot twist! Loading data is only half the story. The real test comes when users start creating visualizations and demanding insights.
- Import mode: Visual Load takes 4.38 seconds, it was slow to load, but when it comes to plotting the visuals, import mode is quick, smooth, and reliable.
- Direct Lake took a bit longer at 12.4 seconds. Still impressive, but not quite the visualization speed demon we expected.
- DirectQuery: It takes 89 seconds for visuals. It seems like someone goes for morning walk and starts gossiping with his friend in a tea stall.
Winner: Import mode
Overall, Winner: Based on data load and plotting visuals Direct Lake will be the best choice for large dataset.
Case 2: Contoso BI Dataset (3.41M rows)
Now let’s switch gears from the crowded streets of New York taxis to a tidy shopping mall with the Contoso BI dataset, a star schema in total over 3 million rows.
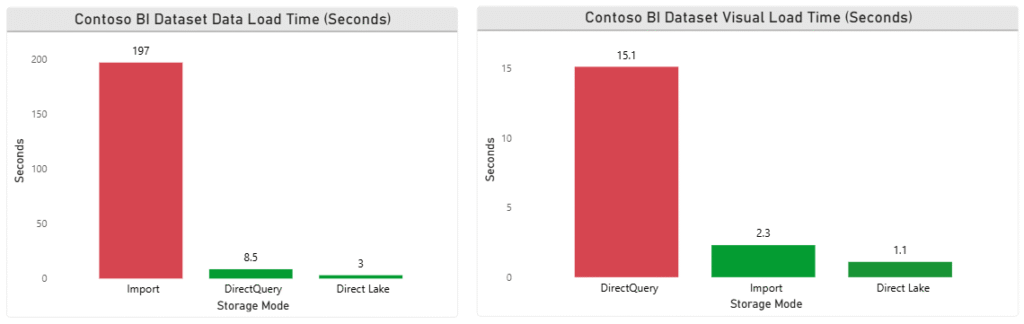
Data Load:
- Import Mode: It was like a careful chef preparing a three-course meal steady but slow, taking about 197 seconds (~3.3 minutes).
- DirectQuery: zipped in at 8.5 seconds, like a courier on a scooter weaving through traffic.
- Direct Lake: Once again stole the spotlight, crossing the finish line in just 3 seconds. Slightly slower than with the NYC flat file (because this time it had to juggle three tables instead of one) but still lightning-fast.
Winner: Direct Lake
Visual Load:
- Import Mode wasn’t far behind, pulling off its trick in 2.3 seconds, still smooth and reliable.
- DirectQuery, however, played the slow drummer in the band, dragging visuals out over 15.1 seconds long enough for you to check your phone notifications before the chart appeared.
- Direct Lake: It turned into a magician, making visuals appear in 1.1 seconds, blink and you’d miss it.
Winner: Direct Lake
Overall, Winner: When it comes to small or medium size dataset, it’s better to choose Direct Lake or Import mode to get a fast and smooth performance.
Conclusion: Choosing the Right Storage Mode in Fabric
If you’re working with massive datasets, Direct Lake is a breakthrough offering near instant loading and scalability without the Import bottlenecks. However, if your priority is to make faster visual interaction on smaller datasets, Import Mode still delivers the smoothest experience. DirectQuery, while useful for real-time scenarios, may not be the best fit for analytics-heavy workloads.Ultimately, the choice of storage mode depends on your data size, query frequency, and user experience expectations.































